В “Поглед върху речниковия състав на някои български автори” разгледахме лексикалното богатство на някои от най-известните родни творци и отхвърлихме идеята за потенциално сравнение с английските им колеги. Сега ще обсъдим още някои характеристики на данните, както и методологията на изследването.
Ще започнем с кратко резюме на получените резултати. Разгледахме първите 200 000 думи от произведенията на няколко автора. След това преброихме колко различни думи се срещат в тези 200 000, използвайки проста и ясна дефиниция - две думи са различни, ако се различават в изписването си. Така маса и маси се броят за две думи, въпреки че основната им форма е една и съща. Съответно две думи се смятат за еднакви, ако се изписват по един и същ начин - маса от изразите “кухненска маса” и “маса на атома” ще се преброи веднъж, въпреки че смисълът е различен. Накрая сравнихме броя уникални думи на авторите, и донякъде затвърдихме тезата, че Вазов е имал най-богат речников състав.
Защо обаче използваме точно това определение за различни и еднакви думи? Защо разглеждаме точно първите 200 000 думи, а не всичките? Тези въпроси ще разгледаме в настоящата статия.
Думите маси и масата са част от една и съща лексема - или множество думи с еднакво значение и разлика само във формата. Употребата и на двата варианта не обогатява речника на използващия ги - така че защо не ги преброим само веднъж? За целта трябва да ги нормализираме и от формата масата да получим основната форма (или лема) - маса. За съжаление, този процес е труден за автоматизиране - в българския език няма строги, винаги валидни правила за образуване на различните форми. Например думите котка и ръка изглеждат сходни - и двете са в женски род и завършват по един и същ начин, но формите им за множествено число значително се различават - котки и ръце.
Традиционният подход за нормализация е ръчен - човек чете текста и записва основната форма на всяка следваща дума. Главното предимство на този метод е, че хората извършват тази задача със сравнителна лекота - особено ако търсим уникалните думи в един разказ например. Когато става въпрос за милиони думи обаче, такова начинание би отнело твърде много време. Освен това, ако извършваме подобно, но не напълно еднакво действие многократно, ще започнем да правим все повече грешки. Читателите с повече свободно време могат да направят експеримент и да съберат 10 000 двойки многоцифрени числа - след което да повторят операцията и да проверят дали ще получат същите резултати.
Поради такива причини хората, занимаващи се с компютърна лингвистика и обработка на естествен език, са създали различни алгоритми за определяне на основната форма на дума. Тъй като са автоматични, те могат да се използват за големи количества данни. Двата основни варианта носят звучните имена лематизация и стеминг. Границата между тях е малко размита, но тук ще изясним основните им характеристики.
Лематизацията е по-точен, но по-бавен подход, в който обикновено се използва речник от различните форми на дадена дума към основната - например (маси → маса), (масите → маса) и т.н. След това се определят допълнителни детайли за разглежданата дума с цел по-голяма точност. Например само от думата казана не знаем дали това е членуваната форма на съд за варене на алкохолни напитки, или част от народната мъдрост “Казана дума, хвърлен камък”. Ако обаче знаем, че казана е прилагателно име от женски род, решението е по-лесно. (Такава информация можем да получим от алгоритми за определяне частите на речта, или part-of-speech tagging.) Основният проблем е, че езикът е динамичен и се променя постоянно, ала речникът е статичен
- един речник, съставен през 2015 година, не може да съдържа думите, които младежите през 2080-та ще използват, нито тези, които Иван Вазов и Елин Пелин са използвали в началото на XX-ти век. Освен това, алгоритмите за определяне частите на речта са сложни за създаване, и може да не са напълно точни, което също влияе на качеството на лематизацията.
Стемингът е по-бърз и неточен метод, който използва конкретни характеристики на езика. Обикновено се състои от правила за премахване на наставки - тип “Ако думата завършва на -ът, основната форма се получава, като -ът се премахне” (мъжът → мъж, но ако правилото е толкова просто, може да доведе и до грешки - например път → п). Освен това при този подход не се получава истинската основна форма на думата, а така нареченият стем. Например от правилото “Ако думата завършва на -ият, премахваме -ият” и думата големият ще получим стема голем, вместо основната форма голям.
На следващата графика ще покажем броя уникални леми в първите 200 000 думи на авторите, използвайки готов алгоритъм за лематизация. Алгоритъмът използва речник от двойки (дума → основна форма), но не използва допълнителна информация - например не се определя каква част на речта е всяка от думите. Освен това, ако някоя дума не е в речника, тя се игнорира напълно - така думата пивопийци, използвана от Вазов, няма да се преброи, защото не е част от един съвременен речник.
В сравнение с предишните резултати, тук числата са доста по-малки - за пример, Емилиян Станев е използвал близо 28 000 уникални думи, но само 12 000 уникални леми. Това е причинено от разгледаната в предходната статия особеност на българския език - една лема може да има множество различни форми според употребата си. За разлика от резултатите от анализа на уникални думи, изглежда, че Вазов не е използвал най-много уникални леми. На пръв поглед Вера Мутафчиева и Блага Димитрова са използвали малко повече различни леми от него.
Несъотвествието между броя уникални думи и уникални леми би могло да се случи например, ако Блага Димитрова е писала само в сегашно време и мъжки род. Тогава броят уникални думи, които тя е използвала, ще е много близък до броя уникални леми, тъй като няма да има разнообразие във формите на думите. Съответно, ако Вазов е използвал същите леми, но в повече родове и числа, той ще излезе по-напред при сравнението по брой уникални думи.
В случая обаче това несъотвествие е причинено от алгоритъма - както отбелязахме и преди, Вазов е използвал множество архаични и народни думи, които дори по негово време не са били в официалните речници, а какво остава за един съвремен речник. Поради тази особеност си струва да повторим анализа с малка модификация - ако някоя дума не се среща в речника, тя се брои за уникална лема. Така за лема на пивопийци ще приемем самата дума, вместо единственото число пивопиец. Разбира се, това отново не е перфектно, тъй като пивопийци и пивопийците ще се преброят като две различни думи - а първоначалната цел беше да избегнем точно това.
Тази графика повече наподобява резултатите от предишната статия. Основната разлика е, че Елин Пелин и Димитър Димов си разменят петото и шестото място.
Горното изложение хвърля малко светлина върху възможностите за преброяване на различните думи. Разглеждането на уникални думи е лесно за разбиране и обяснение и има ясни недостатъци. Лематизацията и стеминга са нетривиални за реализация, по-сложни за описание и водят до трудни за забелязване неточности, когато са използвани за целта на такова изследване. Това обуславя и отхвърлянето на тези методи от първоначалния анализ.
Друг интересен въпрос е защо разглеждаме фиксиран брой думи. Бихме могли директно да сравним уникалните думи в трудовете на авторите. Това обаче би дало несправедливо предимство на автори с по-обширно творчество. Така романисти като Александър Дюма, чието заплащане се е определяло според броя написани думи, силно биха изкривили подобно сравнение.
Едно привидно подобрение на този подход е да определим каква част от думите, написани от даден автор, са уникални. Димитър Димов например е използвал около 410 000 думи в трите си романа (“Поручик Бенц”, “Осъдени души” и “Тютюн”). Сред тях има 39 000 различни. Можем да дефинираме “оценка за уникалност” като броя уникални думи, разделен на всички думи в творчеството на автора - за Димов това е 39 000 / 410 000 = 9.5%. Тази оценка можем да пресметнем за останалите писатели и просто да определим кой е с най-добър резултат - по-голяма оценка означава повече уникални думи - съответно и по-добро представяне в текущото сравнение.
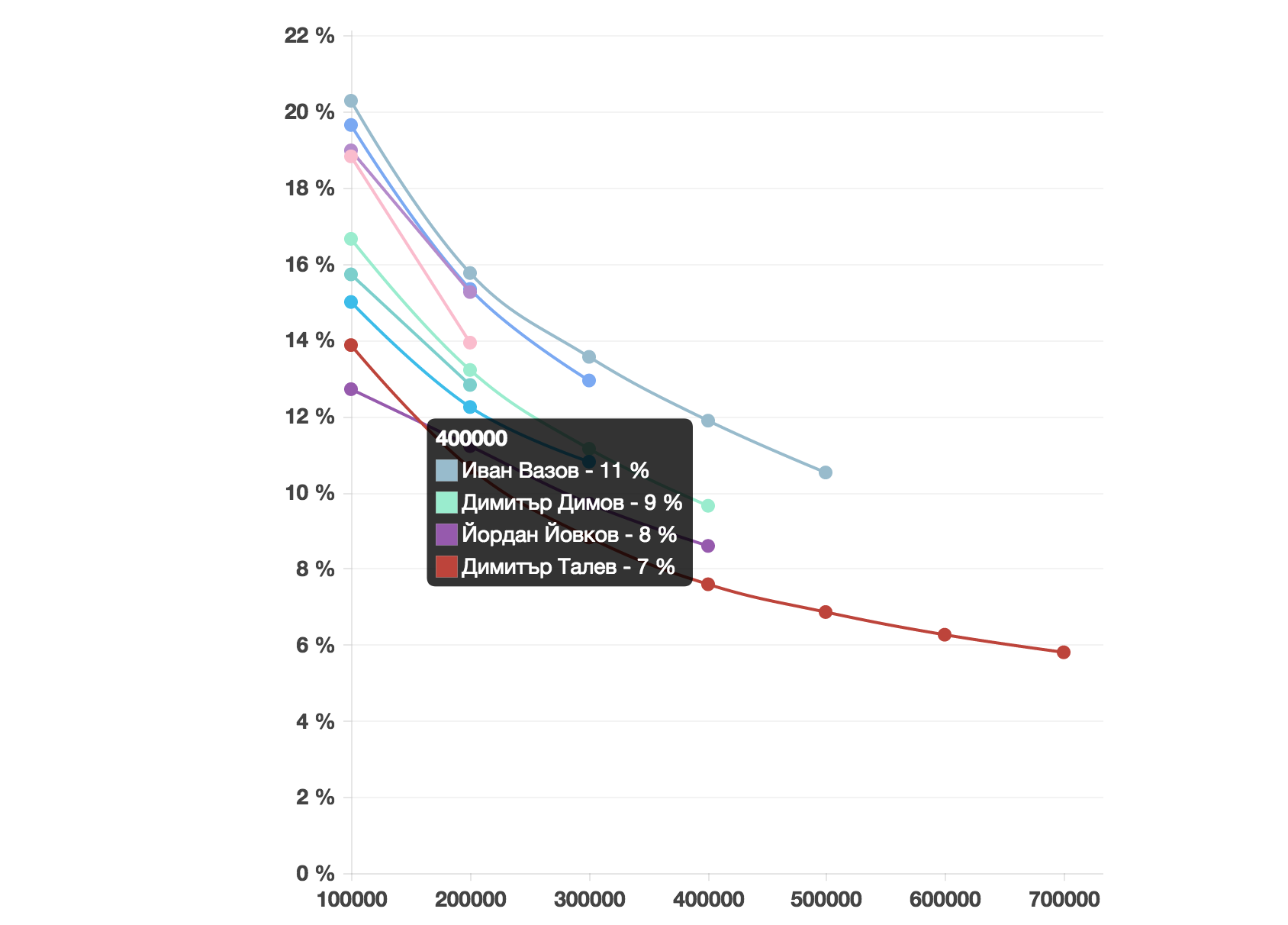
С този подход има един сериозен проблем. Ако сътворим изречение с десет думи, е напълно възможно всичките десет да са уникални - така бихме му дали оценка от 100%. Ако обаче продължим да пишем, ще става все по-трудно да използваме само думи, които не сме използвали досега. Така когато изпишем 1000 думи, ще сме използвали може би 600 различни и ще имаме оценка за уникалност 60%. Въпреки че сме използвали 6 пъти по-богат речник, отколкото в началото, оценката ни е значително по-ниска. Затова не е коректно да сравняваме двама автори по тази оценка, ако единият е написал един милион думи, а другият - 100 000.
На следващата графика е показана оценката за уникалност за разгледаните автори в зависимост от броя анализирани думи. Уникалните думи се дефинират по начина от предишната статия.
Ако разгледаме оценките за уникалност за фиксиран брой анализирани думи - да кажем 200 000, ще получим подобни резултати като от първоначалното изследване - ако преди някой автор е имал 25 000 уникални думи, в случая ще има 25 000, разделено на 200 000. Това не оказва влияние на реда. Ако обаче разгледаме оценката за уникалност на всеки автор за броя думи, които общо сме анализирали за него, подредбата би се променила значително. Например Вазов има само 10% уникални думи от 500-те хиляди анализирани. Това би го поставило след 4 други автора. Всеки от тях обаче е написал по-малко думи от Вазов (поне в разгледаните произведения). Както обсъдихме, това дава преднина на авторите с по-скромно по обем творчество - и затова не би могло да е основа за справедливо сравнение.
Във всяко изследване трябва да се взимат решения. Обикновено те целят да създадат най-добрите възможни условия, но понякога са обусловени от технически или други ограничения. В такива случаи е трудно да се подобри изследването, но съответните решения се оповестяват, за да е ясно какви неточности може да са допуснати и защо. Например текущият анализ не разглежда подсъзнателните решения, взети от автора, тъй като методите на съвременната психология все още не позволяват това. :)
Благодарности
Благодаря на Ани за идеите и строгия качествен контрол, и на Васко за холистичния поглед върху данните. Също така - на Божидар за използвания негов проект.
-
Поглед върху речниковия състав на някои български автори - оригиналното изследване.
-
Основата на използвания алгоритъм за лематизация, написана от Божидар Божанов